
以前、『Scikit-learnカリフォルニア住宅価格データセットで深層ニューラルネットワークしてみる』『Scikit-learn乳がん診断データセットで深層ニューラルネットワークしてみる』これらの記事で各々回帰と分類をDNNでやりました。今回は、【Scikit-learn】手書き数字データセットでやろうと思います。画像の分類を、全結合層だけでやってみるという内容です。
データの確認とか準備とか
importimport numpy as np
import pandas as pd
import matplotlib.pyplot as plt
plt.style.use("ggplot")
from keras import models
from keras import layers
from keras.callbacks import EarlyStopping
from sklearn.model_selection import train_test_splitいつものように、必要なライブラリをインポート。
from sklearn.datasets import load_digits
digits=load_digits() この、load_digits()でデータを呼び出します。
print(digits.images.shape)
print(digits.data.shape)
print(digits.target.shape)(1797, 8, 8)
(1797, 64)
(1797,)images/data/targetに各々こんな型でデータが入ります。
- images:1797個の8×8の行列
- data:1797個の64個の値を持つベクトル
- target:1797個の正解データ
imagesのデータを少し見てやると、
plt.gray()
plt.matshow(digits.images[0])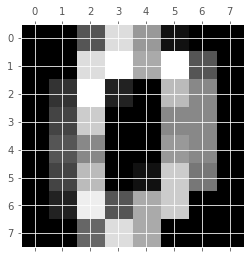
digits.target[0]0ということで、1個目のデータはゼロの手書き数字で、正解もゼロというわけです。これが1797個ありますよと。dataの方も見てやると、
digits.data[0]array([ 0., 0., 5., 13., 9., 1., 0., 0.,
0., 0., 13., 15., 10., 15., 5., 0.,
0., 3., 15., 2., 0., 11., 8., 0.,
0., 4., 12., 0., 0., 8., 8., 0.,
0., 5., 8., 0., 0., 9., 8., 0.,
0., 4., 11., 0., 1., 12., 7., 0.,
0., 2., 14., 5., 10., 12., 0., 0.,
0., 0., 6., 13., 10., 0., 0., 0.])8×8の行列が1個のベクトルに変換されています。画像と見比べると、各位置の色の濃淡が一つの数字で表現されています。
print(np.unique(digits.data))
print(np.unique(digits.target))[ 0. 1. 2. 3. 4. 5. 6. 7. 8. 9. 10. 11. 12. 13. 14. 15. 16.]
[0 1 2 3 4 5 6 7 8 9]ということで、色の濃淡は17段階で表現され、正解データは0~9までの数字となっています。
中身が概ね分かったところで、学習のためのデータを用意していきます。
x=digits.data/16
t_=digits.targetxは16で割って正規化しておきます。
t_array([0, 1, 2, ..., 8, 9, 8])先に見た通り、これは1797個の0~9までの数字です。
最終の出力は、一個のdataベクトルに対し、0~9各々対する確率を出力させるので、
入力もこの形に合わせます。
t=pd.get_dummies(t_)
t=t.values
tarray([[1, 0, 0, ..., 0, 0, 0],
[0, 1, 0, ..., 0, 0, 0],
[0, 0, 1, ..., 0, 0, 0],
...,
[0, 0, 0, ..., 0, 1, 0],
[0, 0, 0, ..., 0, 0, 1],
[0, 0, 0, ..., 0, 1, 0]], dtype=uint8)データフレームからndarrayに戻しています。
一個目は、正解0だったので、左端に1他0となっています。
x_train,x_test,t_train,t_test=train_test_split(x,t,test_size=0.3,random_state=0)
x_train,x_train_val,t_train,t_train_val=train_test_split(x_train,t_train,test_size=0.2,random_state=0)
print(x_train.shape,x_train_val.shape,x_test.shape)
print(t_train.shape,t_train_val.shape,t_test.shape)(1005, 64) (252, 64) (540, 64)
(1005, 10) (252, 10) (540, 10)データを分けて準備完了です。
モデルの構築と学習
多値分類なので、出力層の活性化関数はソフトマックス関数に指定します。
model=models.Sequential()
model.add(layers.Dense(1024,activation="relu",input_dim=64))
model.add(layers.Dense(512,activation="relu"))
model.add(layers.Dense(256,activation="relu"))
model.add(layers.Dense(128,activation="relu"))
model.add(layers.Dense(64,activation="relu"))
model.add(layers.Dense(32,activation="relu"))
model.add(layers.Dense(16,activation="relu"))
model.add(layers.Dense(10,activation="softmax"))仰々しいですが、まあ、こんなでやってみます。
model.compile(optimizer="adam",
loss="categorical_crossentropy",
metrics=["accuracy"])
callbacks=[EarlyStopping(monitor="val_accuracy",patience=10)]
results=model.fit(x_train,
t_train,
epochs=1000,
batch_size=80,
verbose=1,
callbacks=callbacks,
validation_data=(x_train_val,t_train_val))最適化方法やら、損失関数やら、評価指標を決めて学習です。
サクッと終わって、結果を見ると、
pred_x_test=model.predict(x_test)
np.round(pred_x_test)array([[0., 0., 1., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 1., 0.],
[0., 0., 1., ..., 0., 0., 0.],
...,
[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 1., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 1.]], dtype=float32)各々確率で出力されるので、roundで丸めています。
testデータに対して、1個目は2、2個目は8、3個目は2…という予測をしてくれています。
正解率は、
from sklearn import metrics
print(metrics.accuracy_score(t_train,np.round(model.predict(x_train))))
print(metrics.accuracy_score(t_train_val,np.round(model.predict(x_train_val))))
print(metrics.accuracy_score(t_test,np.round(model.predict(x_test))))1.0
0.9761904761904762
0.9777777777777777このぐらいのデータだからなのでしょう、全結合だけでも98%近い正解率を得ました。
畳み込みやプーリングを使うと、ここからさらに上がるんでしょうね。

