
前回のこちら『【kaggle】宇宙船タイタニック!?データ整理編』であらかたデータを整えたので
今回は学習からカグル提出した結果まで、やっていこうと思います。
学習用データに編集していきます
前回でここまでやりました。
df_all.info()<class 'pandas.core.frame.DataFrame'>
RangeIndex: 12970 entries, 0 to 12969
Data columns (total 21 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 PassengerId 12970 non-null object
1 HomePlanet 12970 non-null object
2 CryoSleep 12970 non-null bool
3 Cabin 12671 non-null object
4 Destination 12970 non-null object
5 Age 12970 non-null float64
6 VIP 12970 non-null bool
7 RoomService 12970 non-null float64
8 FoodCourt 12970 non-null float64
9 ShoppingMall 12970 non-null float64
10 Spa 12970 non-null float64
11 VRDeck 12970 non-null float64
12 Name 12676 non-null object
13 Transported 8693 non-null float64
14 train/test 12970 non-null object
15 ID01 12970 non-null int64
16 ID02 12970 non-null int64
17 Cabin1 12970 non-null object
18 Cabin2 12970 non-null int64
19 Cabin3 12970 non-null object
20 pay 12970 non-null float64
dtypes: bool(2), float64(8), int64(3), object(8)
memory usage: 1.9+ MB名前は今回使わないので落とします。
df_all=df_all.drop(["Name"],axis=1)文字のデータをラベルエンコーディングします。
from sklearn.preprocessing import LabelEncoder
lbl=LabelEncoder()df_all["HomePlanet"]=lbl.fit_transform(df_all["HomePlanet"])
df_all["Destination"]=lbl.fit_transform(df_all["Destination"])
df_all["Cabin1"]=lbl.fit_transform(df_all["Cabin1"])
df_all["Cabin3"]=lbl.fit_transform(df_all["Cabin3"])確認すると、
df_all.head()| PassengerId | HomePlanet | CryoSleep | Cabin | Destination | Age | VIP | RoomService | FoodCourt | ShoppingMall | Spa | VRDeck | Transported | train/test | ID01 | ID02 | Cabin1 | Cabin2 | Cabin3 | pay | |
| 0 | 0001_01 | 1 | FALSE | B/0/P | 2 | 39 | FALSE | 0 | 0 | 0 | 0 | 0 | 0 | train | 1 | 1 | 1 | 1 | 0 | 0 |
| 1 | 0002_01 | 0 | FALSE | F/0/S | 2 | 24 | FALSE | 109 | 9 | 25 | 549 | 44 | 1 | train | 2 | 1 | 5 | 1 | 1 | 736 |
| 2 | 0003_01 | 1 | FALSE | A/0/S | 2 | 58 | TRUE | 43 | 3576 | 0 | 6715 | 49 | 0 | train | 3 | 1 | 0 | 1 | 1 | 10383 |
| 3 | 0003_02 | 1 | FALSE | A/0/S | 2 | 33 | FALSE | 0 | 1283 | 371 | 3329 | 193 | 0 | train | 3 | 2 | 0 | 1 | 1 | 5176 |
| 4 | 0004_01 | 0 | FALSE | F/1/S | 2 | 16 | FALSE | 303 | 70 | 151 | 565 | 2 | 1 | train | 4 | 1 | 5 | 1 | 1 | 1091 |
数字になってくれました。さらに、使わないのを落とします。
df_all=df_all.drop(["PassengerId","Cabin","ID01"],axis=1)学習用データを形成します。
x=df_all.loc[(df_all["train/test"]=="train")].drop(["Transported","train/test"],axis=1)
t=df_all.loc[(df_all["train/test"]=="train")].iloc[:,10:11]x.head()| HomePlanet | CryoSleep | Destination | Age | VIP | RoomService | FoodCourt | ShoppingMall | Spa | VRDeck | ID02 | Cabin1 | Cabin2 | Cabin3 | pay | |
| 0 | 1 | FALSE | 2 | 39 | FALSE | 0 | 0 | 0 | 0 | 0 | 1 | 1 | 1 | 0 | 0 |
| 1 | 0 | FALSE | 2 | 24 | FALSE | 109 | 9 | 25 | 549 | 44 | 1 | 5 | 1 | 1 | 736 |
| 2 | 1 | FALSE | 2 | 58 | TRUE | 43 | 3576 | 0 | 6715 | 49 | 1 | 0 | 1 | 1 | 10383 |
| 3 | 1 | FALSE | 2 | 33 | FALSE | 0 | 1283 | 371 | 3329 | 193 | 2 | 0 | 1 | 1 | 5176 |
| 4 | 0 | FALSE | 2 | 16 | FALSE | 303 | 70 | 151 | 565 | 2 | 1 | 5 | 1 | 1 | 1091 |
すっきりしました。
t.head()| Transported | |
| 0 | 0 |
| 1 | 1 |
| 2 | 0 |
| 3 | 0 |
| 4 | 1 |
テスト用データも。
x_test=df_all.loc[(df_all["train/test"]=="test")].drop(["Transported","train/test"],axis=1)もろもろ整いました。
OPTUNA×lightGBM×交差検証で学習
さて、やっていきます。
from sklearn.model_selection import train_test_split
from sklearn import metrics
import lightgbm as lgb
from sklearn.model_selection import StratifiedKFoldkf=StratifiedKFold(n_splits=10, shuffle=True, random_state=0)ひとまず10回で。
def objective(trial):
params={"metric":"auc",
"objective":"binary",
"max_depth":trial.suggest_int("max_depth",5,1000),
"num_leaves":trial.suggest_int("num_leaves",10,3000),
"min_child_samples":trial.suggest_int("min_child_samples",50,500),
"learning_rate":trial.suggest_uniform("learning_rate",0.01,1.5),
"feature_fraction":trial.suggest_uniform("feature_fraction",0,1),
"bagging_fraction":trial.suggest_uniform("bagging_fraction",0,1)}
val_scores=[]
for i, (train__, val__) in enumerate(kf.split(x,t)):
x_train, x_val=x.iloc[train__], x.iloc[val__]
t_train, t_val=t.iloc[train__], t.iloc[val__]
lgb_train=lgb.Dataset(x_train, t_train)
lgb_eval=lgb.Dataset(x_val, t_val)
lgbm=lgb.train(params,
lgb_train,
valid_sets=lgb_eval,
num_boost_round=1000,
early_stopping_rounds=50,
verbose_eval=False)
t_train_pred=np.round(lgbm.predict(x_train))
t_val_pred=np.round(lgbm.predict(x_val))
scoretrain=metrics.accuracy_score(t_train["Transported"],t_train_pred)
scoreval=metrics.accuracy_score(t_val["Transported"],t_val_pred)
val_scores.append(scoreval)
cv_score=np.mean(val_scores)
return cv_scoreOPTUNAが選んだ1組のハイパーパラメータで、10回交差検証やって、検証データの正解率の平均を出し、これを最大化(最小化)するハイパーパラメータ見つけてね。と書いています。
study=optuna.create_study(direction="maximize")
study.optimize(objective, n_trials=50)ここで最大化を指定し、50回探索します。
Best is trial 31 with value: 0.8131795034588574ということで、31回目の探索で検証データの平均最大81.3%という結果でした。
ベストなハイパーパラメータが分かったので、これでモデルを作ります。
x_train,x_val,t_train,t_val=train_test_split(x,t,test_size=0.25,stratify=t)
lgb_train=lgb.Dataset(x_train, t_train)
lgb_eval=lgb.Dataset(x_val, t_val)あらためて、データを定義して、
bestparams={"metric":"auc",
"objective":"binary",
"max_depth":study.best_params["max_depth"],
"num_leaves":study.best_params["num_leaves"],
"min_child_samples":study.best_params["min_child_samples"],
"learning_rate":study.best_params["learning_rate"],
"feature_fraction":study.best_params["feature_fraction"],
"bagging_fraction":study.best_params["bagging_fraction"]}
best_lgbm=lgb.train(bestparams,
lgb_train,
valid_sets=lgb_eval,
num_boost_round=1000,
early_stopping_rounds=50,
verbose_eval=50)ベストパラムでモデル化。このモデルでテストデータに対する予測をします。
pred=np.round(best_lgbm.predict(x_test))ちなみにベストパラムはこんな。
study.best_params{'bagging_fraction': 0.4905227000093506,
'feature_fraction': 0.9874276185548546,
'learning_rate': 0.1606778267851563,
'max_depth': 920,
'min_child_samples': 200,
'num_leaves': 236}訓練データと検証データの正解率も見ておく。
print(metrics.accuracy_score(t_train["Transported"],np.round(best_lgbm.predict(x_train))))
print(metrics.accuracy_score(t_val["Transported"],np.round(best_lgbm.predict(x_val))))0.8476760239300506
0.8150873965041399まあまあってとこですかね?
提出用データ形成と結果
作っていきます。
df_predict=pd.DataFrame(pred.astype(int),columns=["Transported"])
df_predict["Transported"]=df_predict["Transported"].astype(bool)整数にして、さらにbool値で出さなきゃなので変換。
df_submission=pd.concat([df_test["PassengerId"],df_predict],axis=1)テストデータのIDくっつけて完成!さてはて、結果は!?
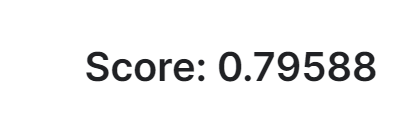
うーん、いまいち。上位は81%越えています。IDのとこの前の数字とか、キャビンの真ん中の数字とか、名前とか、このあたりもっとやるともうちょい上がりそうな気がしてます。
