
AIやら機械学習やらは、ある程度のデータ数があることが前提になってる気がするのですが、
めっちゃ少ないデータだとどうなるの、が見たくなったのでやってみます。
どうなるかが、想像しにくい、前回『サポートベクトルマシンの予測平面を描画してみる』も扱った
サポートベクトルマシン(ガウシアンカーネル、分類)で見てみようと思います。
少ないデータを用意
まずは、こんなやつで、
import numpy as np
import matplotlib.pyplot as plt
plt.style.use("ggplot")
x=np.array([[ 0,1],[np.sqrt(3)/2,-0.5],[-np.sqrt(3)/2,-0.5]])
y=np.array([0,1,2])半径1の円上に各頂点を持つ正三角形で、クラスを3つに。
def plot_datasets(x,y):
plt.plot(x[:,0][y==0],x[:,1][y==0],"o",c="blue",ms=15,alpha=0.2)
plt.plot(x[:,0][y==1],x[:,1][y==1],"^",c="red",ms=15,alpha=0.2)
plt.plot(x[:,0][y==2],x[:,1][y==2],"s",c="green",ms=15,alpha=0.2)
plt.xlabel("x_0",fontsize=20)
plt.ylabel("x_1",fontsize=20)
from matplotlib.colors import ListedColormap
def plot_decision_boundary(clf,x,m=0.2):
_x0=np.linspace(x[:,0].min()-m,x[:,0].max()+m,500)
_x1=np.linspace(x[:,1].min()-m,x[:,1].max()+m,500)
x0,x1=np.meshgrid(_x0,_x1)
x_new=np.c_[x0.ravel(),x1.ravel()]
y_pred=clf.predict(x_new).reshape(x1.shape)
cmap=ListedColormap(["mediumblue","indianred","greenyellow"])
plt.contourf(x0,x1,y_pred,alpha=0.3,cmap=cmap)データプロット用と予測平面描画用の関数を用意。
from sklearn.svm import SVC
svm1=SVC(C=1,gamma=0.1)
svm2=SVC(C=10,gamma=1)
svm3=SVC(C=100,gamma=10)
svm1.fit(x,y)
svm2.fit(x,y)
svm3.fit(x,y)これで各々学習させて見てみます。先の関数で描画すると、
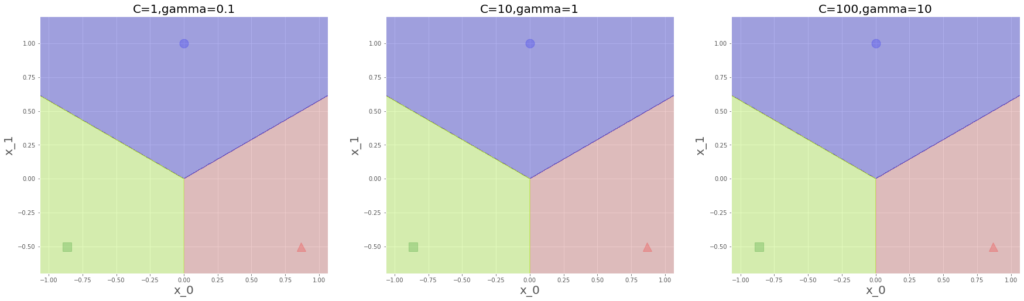
これはまあ予想通りですね、ハードマージン的に距離最大化されているのがわかります。
次々にやってみる
次のデータはこんな、
x=np.array([[ 0,1],[0,0],[0,-1]])
y=np.array([0,1,2])x_1軸上に等間隔で三つプロット。
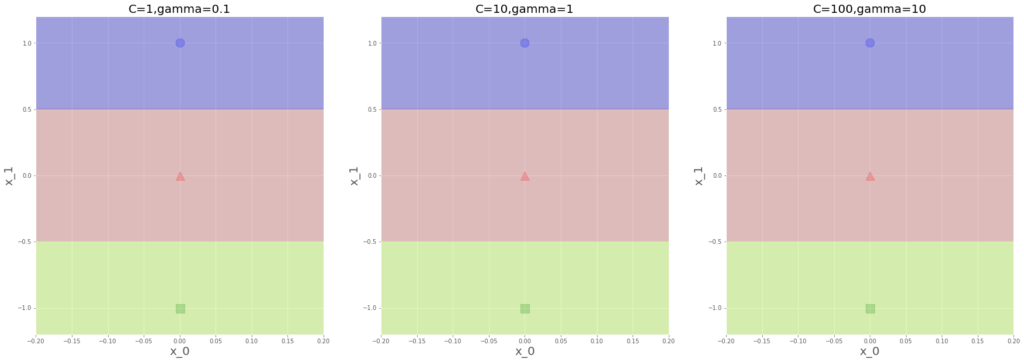
これも、距離最大化で平行な境界線となる、まあそうですよね。
次はこんな、
x=np.array([[ 0,1],[0,0],[0,-1],[-1,0],[1,0]])
y=np.array([0,1,2,0,2]原点と各軸の1、-1で、データを5つに。さあ、どうなりましょうか?
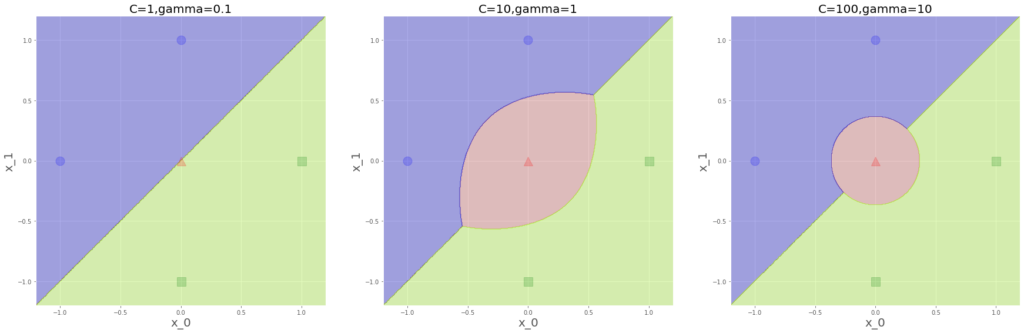
ハイパーパラメータ依存しだしましたね、左端はクラス1の赤いエリアがありません。
青と緑を距離最大で分離することが評価関数を最も小さくする結果になるようです。
各ハイパーパラメータが増えると、
C:誤分類許すまじパワー
gamma:各データ1個1個を重視パワー
が増大し、これらと距離最大化パワーの三つ巴で変化していくと理解しています。
次はこんな、
x=np.array([[ 0,1],[0,0],[0,-1],[-1,0],[1,0],[-0.5,0],[0.5,0]])
y=np.array([0,1,2,0,2,1,1]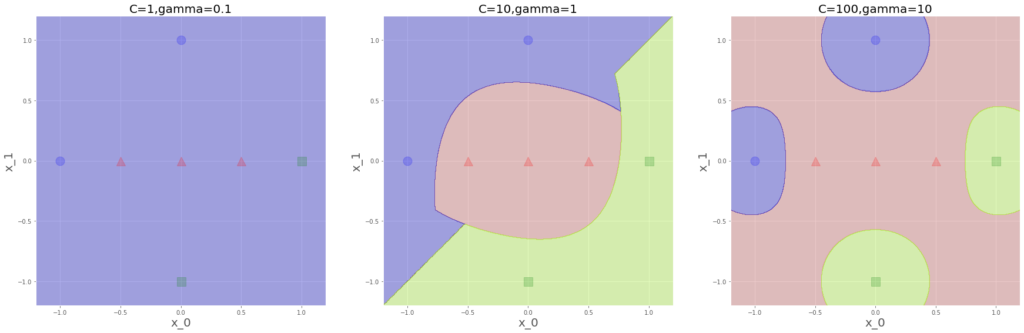
左端は、真っ青になりました。誤判別が結構許されているので、この予測が最も評価関数の値をさげるということなのでしょう。しかし、なんで青(クラス0)何だろう??並びで最初だからか?
また、真ん中は右上に若干青(クラス0)領域が緑(クラス2)領域に食い込んでいます、
基本的に対称になるイメージだったのですが、このはみだし何を意味してるのでしょう。
右端はまあ気持ちがいい感じですね。
次、
x=np.array([[ 0,1],[0,0],[0,-1],[-1,0],[1,0],[-0.5,0],[0.5,0],[0,0.5],[0,-0.5]])
y=np.array([0,1,2,0,2,1,1,0,2])
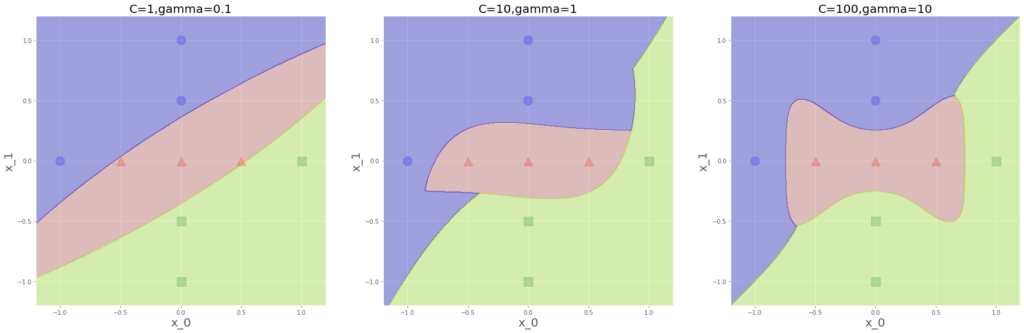
あら、また真ん中の右上、青がせり出しています。このデータ配置なら基本的には、青と緑の領域は同じ面積になるもんだと思っていましたが、、、。
最後、
x=np.array([[ 0,1],[0,0],[0,-1],[-1,0],[1,0],[-0.5,0],[0.5,0],[0,0.5],
[0,-0.5],[0.5,0.5],[-0.5,0.5],[-0.5,-0.5],[0.5,-0.5]])
y=np.array([0,1,2,0,2,1,1,0,2,1,1,1,1])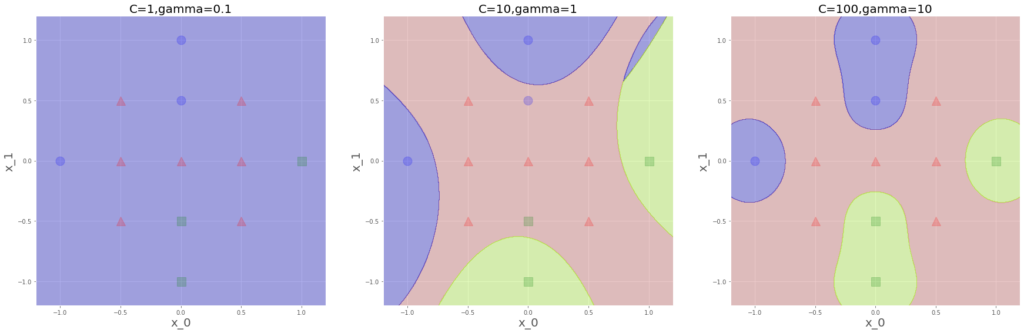
これも、真ん中右上青が出てきますね。こんなとこ青なります??なんか間違えてますかね。。。右端はきれいに分類されてる感じですね。
ざっとみてきましたが、少ないデータでも
C:誤分類許すまじパワー
gamma:各データ1個1個を重視パワー
これらを調整すれば、美しい分類をしてくれます。

