
前回の記事で、『Scikit-learnカリフォルニア住宅価格データセットで深層ニューラルネットワークしてみる』これをやったんです。さすがの深層ニューラルネットワークだね、という結果が得られました。こうなればですね、非深層系では最強との呼び声高い、勾配ブースティング決定木でもやってみて、どうなるの?、が見たくなりました。ので、前回のデータでlightGBMをやってみようと思います。
lightGBMで学習
import lightgbm as lgbこいつをインポートします。
lgb_train = lgb.Dataset(x_train, y_train.ravel())
lgb_val = lgb.Dataset(x_train_val, y_train_val.ravel()) こないして、訓練用と検証用のデータを用意せなあきません。
params = {'metric': 'rmse',
'max_depth' : 20}
lgbm = lgb.train(params,
lgb_train,
valid_sets=lgb_val,
num_boost_round=1000,
early_stopping_rounds=100,
verbose_eval=50)こないして、学習します。
| valid_sets | 検証用データ |
| num_boost_round | ブースティングの回数(木の本数) |
| early_stopping_rounds | 検証用データの評価指標が指定した回数改善しなかったら計算終わってねのやつ |
| verbose_eval | この数字刻みのブースト回数で結果を出力してねのやつ |
ということで、これで学習完了。結果の出力としては、
Training until validation scores don't improve for 100 rounds.
[50] valid_0's rmse: 0.464031
[100] valid_0's rmse: 0.444464
[150] valid_0's rmse: 0.438133
[200] valid_0's rmse: 0.436031
[250] valid_0's rmse: 0.434568
[300] valid_0's rmse: 0.433457
[350] valid_0's rmse: 0.43408
[400] valid_0's rmse: 0.434361
Early stopping, best iteration is:
[302] valid_0's rmse: 0.433316こんなです。
これ、同じ勾配ブースティング決定木を用いたxgboostを使ったことあるんですが、
計算速度が全然違います、さすがlight、めちゃくちゃ速いです。重宝される訳ですね。
モデルの評価
学習、検証、テスト各々のデータで、決定係数を見てやります。さてはて、
print(metrics.r2_score(y_train,lgbm.predict(x_train)))
print(metrics.r2_score(y_train_val,lgbm.predict(x_train_val)))
print(metrics.r2_score(y_test,lgbm.predict(x_test)))
0.9420902329786626
0.8008689316581606
0.8118103058463246テストデータで、前回の深層ニューラルネットワークの結果を越えてきましたね。
すんごい数値です。そりゃ皆さん使うわけですね。
簡単にテストデータの散布図見てやると、
plt.figure(figsize=(10,10))
plt.scatter(y_test.tolist(),lgbm.predict(x_test).tolist(),color="red",alpha=0.1)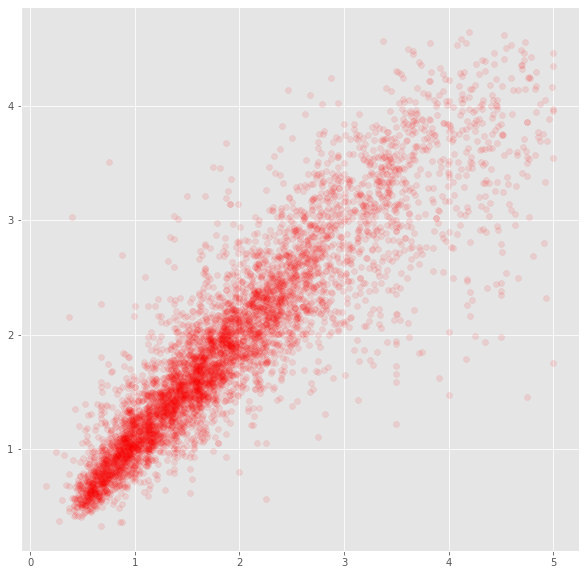
かなり当てはまりの良いモデルができました。
今日はここまで。

