
『【kaggle】タイタニックデータをlightGBMでOPTUNA(シンプルに)』にてサクッとやって、77%でした。もうちょっといいスコア出したいじゃん、ということで、タイトルの通り、三つの力を掛け合わせた結果81%出てくれたので、やったことをまとめていきます。
データの確認やらFeature Engineeringやら
!pip install optunaimport numpy as np
import pandas as pd
import matplotlib.pyplot as plt
plt.style.use("ggplot")
import optuna
import seaborn as snsレギュラーメンバーをインポート、
df_train=pd.read_csv("/content/drive/MyDrive/Colab Notebooks/Machine Learning/data/kaggle/titanic/train.csv")
df_test=pd.read_csv("/content/drive/MyDrive/Colab Notebooks/Machine Learning/data/kaggle/titanic/test.csv")
df_train_=df_train
df_test_=df_test
df_train_["train_test"]="train"
df_test_["train_test"]="test"
df_test_.insert(1,"Survived",np.nan)
df_all=pd.concat([df_train_,df_test_])
df_all.reset_index(drop=True)ざーっと書いていますが、テストデータにはtest、トレインデータにはtrainが入ったtrain_testカラムを追加、さらにテストデータにnanでSurvivedカラムを追加して、上下でガッチャンしました。
※テストとトレイン各々編集すると面倒なので。
データをもろもろやっていきます。
Pclass
plt.figure(figsize=(16,9))
sns.countplot(df_all["Pclass"],hue=df_all["Survived"])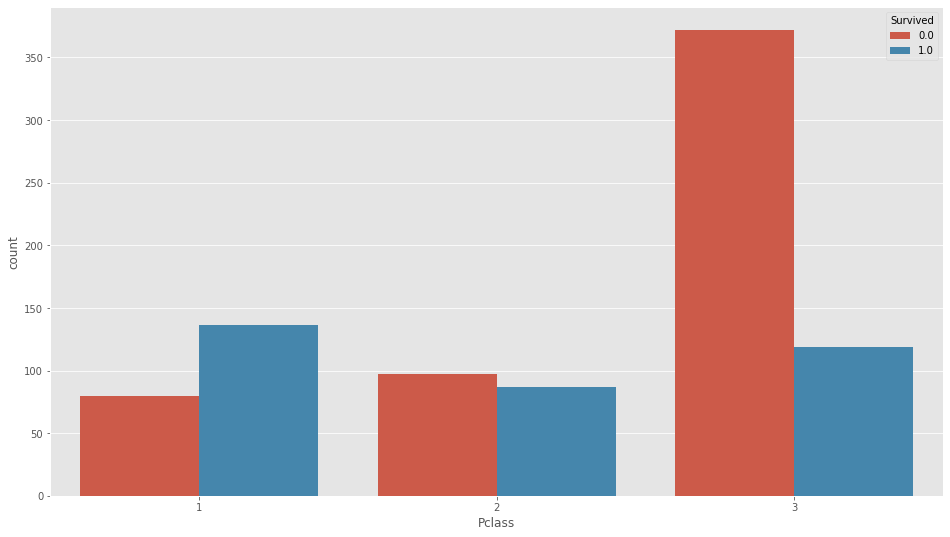
チケットクラス(パッセンジャークラス)ですが、結構分かりやすい特徴でてますね。
Name
df_all["honor"]=df_all["Name"].map(lambda x:x.split(",")[1].split(".")[0])名前から敬称を取り出します。
plt.figure(figsize=(16,9))
sns.countplot(df_all["honor"],hue=df_all["Survived"])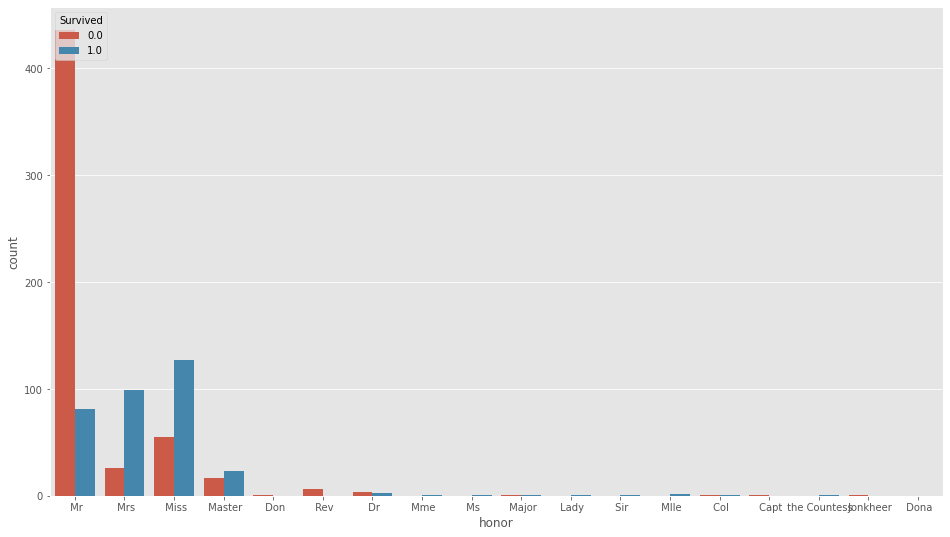
df_all["honor"]=df_all["honor"].replace((" Don"," Rev"," Jonkheer"," Capt"),1)
df_all["honor"]=df_all["honor"].replace((" Mr"),2)
df_all["honor"]=df_all["honor"].replace((" Master"," Dr"," Major"," Col"),3)
df_all["honor"]=df_all["honor"].replace((" Miss",),4)
df_all["honor"]=df_all["honor"].replace((" Mrs"," Mme"," Ms"," Lady"," Sir"," Mlle"," the Countess"," Dona"),5)こんな感じでまとめてしまって、
plt.figure(figsize=(16,9))
sns.countplot(df_all["honor"],hue=df_all["Survived"])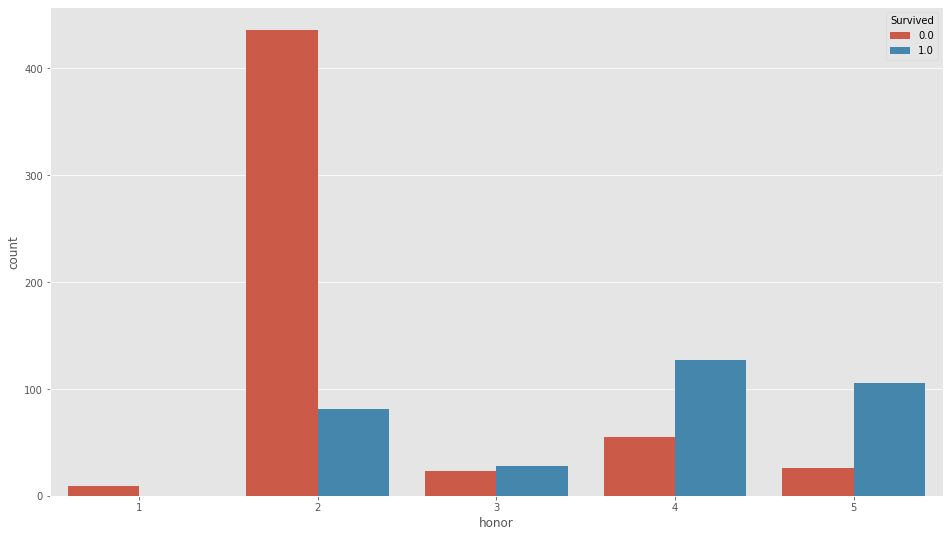
これでやっていきます、さらに名前の長さ
df_all["Namelen"]=df_all["Name"].map(lambda x: len(str(x)))plt.figure(figsize=(16,9))
sns.countplot(df_all["Namelen"],hue=df_all["Survived"])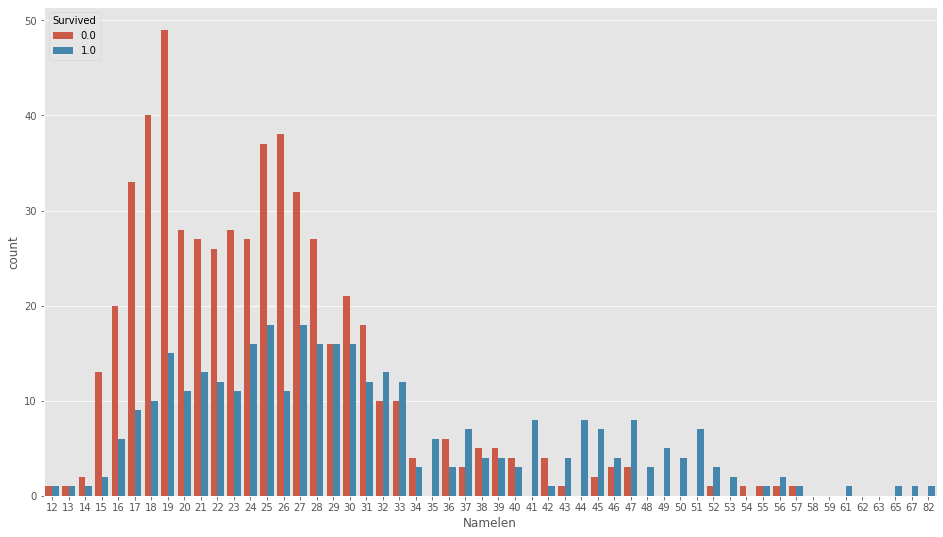
も扱っていきます。さらにさらに、名前の先頭文字も扱います。
df_all["Nameini"]=df_all["Name"].map(lambda x: str(x)[0])plt.figure(figsize=(16,9))
sns.countplot(df_all["Nameini"],hue=df_all["Survived"])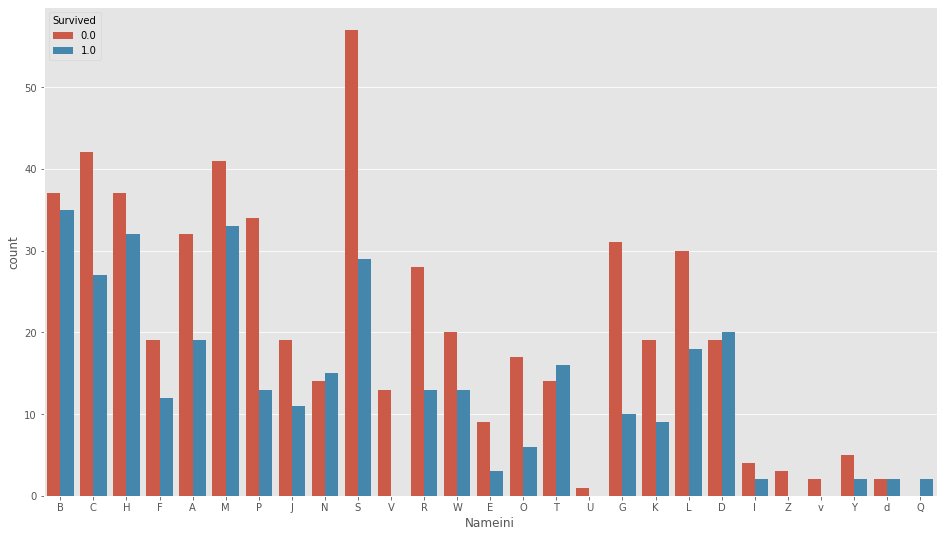
Sex
plt.figure(figsize=(16,9))
sns.countplot(df_all["Sex"],hue=df_all["Survived"])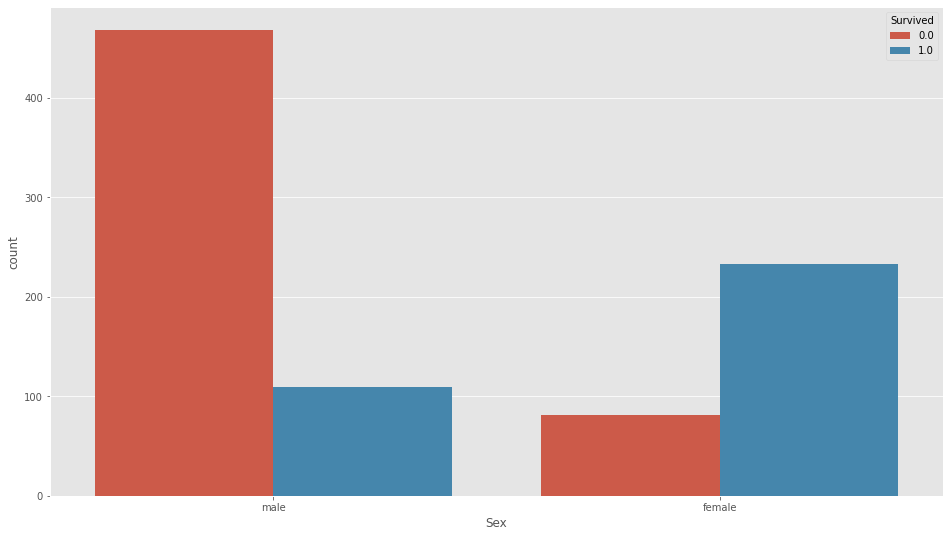
こんななので、性別も扱います。
Age
年齢は300個ぐらい欠損してるので、敬称の中央値で埋めます。
df_all.groupby("honor")["Age"].median()honor
1 41.0
2 29.0
3 7.0
4 22.0
5 35.0
Name: Age, dtype: float64df_all.loc[(df_all["honor"]==1)&(df_all["Age"].isnull()),"Age"]=41.0
df_all.loc[(df_all["honor"]==2)&(df_all["Age"].isnull()),"Age"]=29.0
df_all.loc[(df_all["honor"]==3)&(df_all["Age"].isnull()),"Age"]=7.0
df_all.loc[(df_all["honor"]==4)&(df_all["Age"].isnull()),"Age"]=22.0
df_all.loc[(df_all["honor"]==5)&(df_all["Age"].isnull()),"Age"]=35.0ParchとSibSp
これらは足してさらに1足して家族の人数として、
df_all["Family"]=df_all["Parch"]+df_all["SibSp"]+1plt.figure(figsize=(16,9))
sns.countplot(df_all["Family"],hue=df_all["Survived"])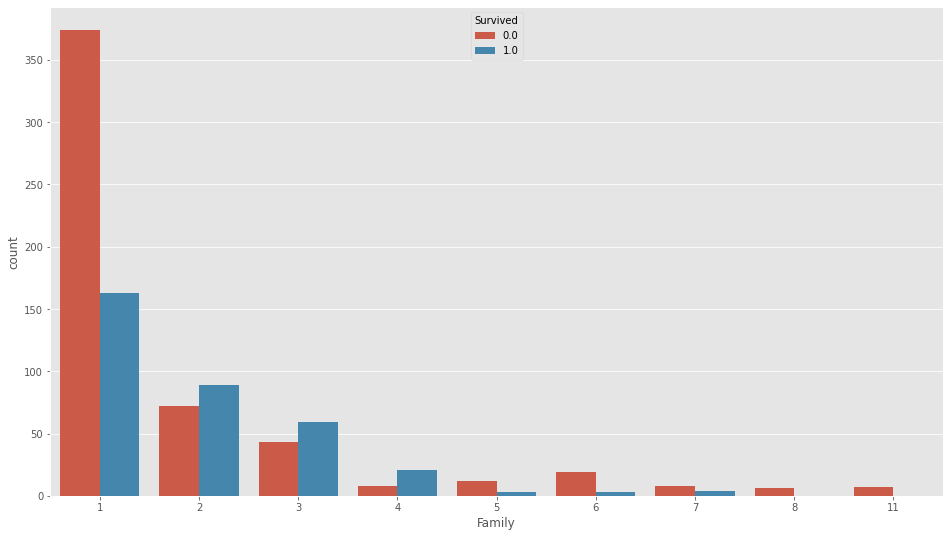
としておきます。
Ticket
df_all["Ticketini"]=df_all["Ticket"].map(lambda x: str(x)[0])
df_all["Ticketlen"]=df_all["Ticket"].map(lambda x: len(str(x)))チケットの先頭文字と文字数を各々こんなでつくります。
plt.figure(figsize=(16,9))
sns.countplot(df_all["Ticketlen"],hue=df_all["Survived"])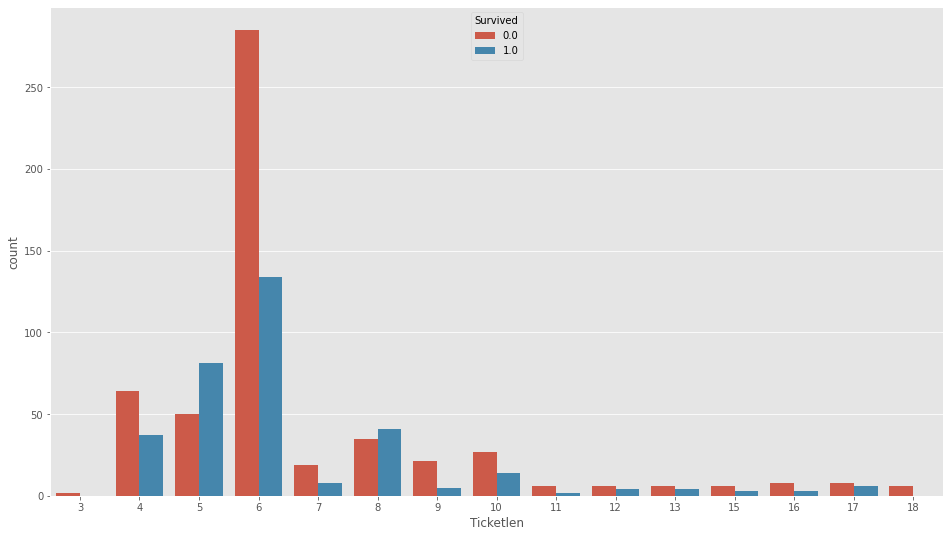
Fare
1個だけ欠損してるので、中央値で埋め。
df_all["Fare"]=df_all["Fare"].fillna(df_all["Fare"].median())Embarked
2個の欠損、最頻値で埋め。
df_all["Embarked"]=df_all["Embarked"].fillna("S")
さて、infoみてやると
df_all.info()<class 'pandas.core.frame.DataFrame'>
Int64Index: 1309 entries, 0 to 417
Data columns (total 19 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 PassengerId 1309 non-null int64
1 Survived 891 non-null float64
2 Pclass 1309 non-null int64
3 Name 1309 non-null object
4 Sex 1309 non-null object
5 Age 1309 non-null float64
6 SibSp 1309 non-null int64
7 Parch 1309 non-null int64
8 Ticket 1309 non-null object
9 Fare 1309 non-null float64
10 Cabin 295 non-null object
11 Embarked 1309 non-null object
12 train_test 1309 non-null object
13 honor 1309 non-null int64
14 Namelen 1309 non-null int64
15 Family 1309 non-null int64
16 Ticketini 1309 non-null object
17 Ticketlen 1309 non-null int64
18 Nameini 1309 non-null object
dtypes: float64(3), int64(8), object(8)
memory usage: 236.8+ KB使うデータを数字に変換します。
from sklearn.preprocessing import LabelEncoder
lbl=LabelEncoder()df_all["Sex"]=lbl.fit_transform(df_all["Sex"])
df_all["Embarked"]=lbl.fit_transform(df_all["Embarked"])
df_all["Ticketini"]=lbl.fit_transform(df_all["Ticketini"])
df_all["Nameini"]=lbl.fit_transform(df_all["Nameini"])使わないデータを落とします。
df_all=df_all.drop(["Name","Ticket","Cabin"],axis=1)df_all.head()| PassengerId | Survived | Pclass | Sex | Age | SibSp | Parch | Fare | Embarked | train_test | honor | Namelen | Family | Ticketini | Ticketlen | Nameini | |
| 0 | 1 | 0 | 3 | 1 | 22 | 1 | 0 | 7.25 | 2 | train | 2 | 23 | 2 | 9 | 9 | 1 |
| 1 | 2 | 1 | 1 | 0 | 38 | 1 | 0 | 71.2833 | 0 | train | 5 | 51 | 2 | 13 | 8 | 2 |
| 2 | 3 | 1 | 3 | 0 | 26 | 0 | 0 | 7.925 | 2 | train | 4 | 22 | 1 | 14 | 16 | 7 |
| 3 | 4 | 1 | 1 | 0 | 35 | 1 | 0 | 53.1 | 2 | train | 5 | 44 | 2 | 0 | 6 | 5 |
| 4 | 5 | 0 | 3 | 1 | 35 | 0 | 0 | 8.05 | 2 | train | 2 | 24 | 1 | 2 | 6 | 0 |
こんな感じになりました。
infoも
df_all.info()<class 'pandas.core.frame.DataFrame'>
Int64Index: 1309 entries, 0 to 417
Data columns (total 16 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 PassengerId 1309 non-null int64
1 Survived 891 non-null float64
2 Pclass 1309 non-null int64
3 Sex 1309 non-null int64
4 Age 1309 non-null float64
5 SibSp 1309 non-null int64
6 Parch 1309 non-null int64
7 Fare 1309 non-null float64
8 Embarked 1309 non-null int64
9 train_test 1309 non-null object
10 honor 1309 non-null int64
11 Namelen 1309 non-null int64
12 Family 1309 non-null int64
13 Ticketini 1309 non-null int64
14 Ticketlen 1309 non-null int64
15 Nameini 1309 non-null int64
dtypes: float64(3), int64(12), object(1)
memory usage: 206.1+ KB数字になってくれてます。あとはトレインとテストを分けて
train=df_all[df_all["train_test"]=="train"]
test=df_all[df_all["train_test"]=="test"]
x=train.drop(["PassengerId","Survived","train_test"],axis=1)
t=train.iloc[:,1:2]
test=test.drop(["PassengerId","Survived","train_test"],axis=1)x.head()| Pclass | Sex | Age | SibSp | Parch | Fare | Embarked | honor | Namelen | Family | Ticketini | Ticketlen | Nameini | |
| 0 | 3 | 1 | 22 | 1 | 0 | 7.25 | 2 | 2 | 23 | 2 | 9 | 9 | 1 |
| 1 | 1 | 0 | 38 | 1 | 0 | 71.2833 | 0 | 5 | 51 | 2 | 13 | 8 | 2 |
| 2 | 3 | 0 | 26 | 0 | 0 | 7.925 | 2 | 4 | 22 | 1 | 14 | 16 | 7 |
| 3 | 1 | 0 | 35 | 1 | 0 | 53.1 | 2 | 5 | 44 | 2 | 0 | 6 | 5 |
| 4 | 3 | 1 | 35 | 0 | 0 | 8.05 | 2 | 2 | 24 | 1 | 2 | 6 | 0 |
これにてデータの準備は完了!!はーつかれた。
lightGBMで学習!!OPTUNAも交差検証もやるよ
いろいろやるのでいろいろインポート。
from sklearn.model_selection import train_test_split
from sklearn import metrics
import lightgbm as lgb
from sklearn.model_selection import StratifiedKFoldkf=StratifiedKFold(n_splits=30, shuffle=True, random_state=0)でここです、交差検証の回数決めてます。何回か挑戦された方はわかると思いますが、とにかくデータによって予測がバンバン変わるので、多めに設定しました。
そして心臓部ですね、lightGBMやOPTUNAのところ
def objective(trial):
params={"metric":"auc",
"objective":"binary",
"max_depth":trial.suggest_int("max_depth",10,500),
"num_leaves":trial.suggest_int("num_leaves",10,500),
"min_child_samples":trial.suggest_int("min_child_samples",100,300),
"learning_rate":trial.suggest_uniform("learning_rate",0.01,0.5),
"feature_fraction":trial.suggest_uniform("feature_fraction",0,1),
"bagging_fraction":trial.suggest_uniform("bagging_fraction",0,1)}
val_scores=[]
for i, (train__, val__) in enumerate(kf.split(x,t)):
x_train, x_val=x.iloc[train__], x.iloc[val__]
t_train, t_val=t.iloc[train__], t.iloc[val__]
lgb_train=lgb.Dataset(x_train, t_train)
lgb_eval=lgb.Dataset(x_val, t_val)
lgbm=lgb.train(params,
lgb_train,
valid_sets=lgb_eval,
num_boost_round=1000,
early_stopping_rounds=50,
verbose_eval=False)
t_train_pred=np.round(lgbm.predict(x_train))
t_val_pred=np.round(lgbm.predict(x_val))
scoretrain=metrics.accuracy_score(t_train["Survived"],t_train_pred)
scoreval=metrics.accuracy_score(t_val["Survived"],t_val_pred)
val_scores.append(scoreval**4/scoretrain**3)
cv_score=np.mean(val_scores)
return cv_scoreこんなにしてみました、工夫と言えば、
val_scores.append(scoreval**4/scoretrain**3)ここで、検証データの方が正解率が大きくなるようなハイパーパラメータを探索してもらうために、
scorevalだけにするんでなくて、これに(scoreval/scoretrain)を3乗でかけてます。いったん3乗にしてますが、もうちょい多くしてもいいかもしれません。
study=optuna.create_study(direction="maximize")
study.optimize(objective, n_trials=50)で50回探索した際の最後が、
Trial 49 finished with value: 0.898618312726408 and parameters:
{'max_depth': 345, 'num_leaves': 408, 'min_child_samples': 184,
'learning_rate': 0.4745765042737584, 'feature_fraction': 0.0059121632054059126, 'bagging_fraction': 0.7107816012173906}.
Best is trial 46 with value: 0.926431855347899.これにて学習完了。
予測値を出してカグルに送信!
ベストなハイパーパラメータが決まりました。
study.best_params{'bagging_fraction': 0.5243524442080566,
'feature_fraction': 0.13376540638688558,
'learning_rate': 0.4074878559558147,
'max_depth': 97,
'min_child_samples': 175,
'num_leaves': 332}ので、これで改めてこれでモデルをつくってテストデータでの予測をします。
x_train,x_val,t_train,t_val=train_test_split(x,t,test_size=0.25,stratify=t)
lgb_train=lgb.Dataset(x_train, t_train)
lgb_eval=lgb.Dataset(x_val, t_val)random_state外しています、なので必ず再現するわけでないですが。。。
bestparams={"metric":"auc",
"objective":"binary",
"max_depth":study.best_params["max_depth"],
"num_leaves":study.best_params["num_leaves"],
"min_child_samples":study.best_params["min_child_samples"],
"learning_rate":study.best_params["learning_rate"],
"feature_fraction":study.best_params["feature_fraction"],
"bagging_fraction":study.best_params["bagging_fraction"]}
best_lgbm=lgb.train(bestparams,
lgb_train,
valid_sets=lgb_eval,
num_boost_round=1000,
early_stopping_rounds=50,
verbose_eval=50)
pred=np.round(best_lgbm.predict(test),3)Training until validation scores don't improve for 50 rounds.
[50] valid_0's auc: 0.866873
Early stopping, best iteration is:
[19] valid_0's auc: 0.87413こんな結果がでてくれて、学習データに対しては、
print(metrics.accuracy_score(t_train["Survived"],np.round(best_lgbm.predict(x_train))))
print(metrics.accuracy_score(t_val["Survived"],np.round(best_lgbm.predict(x_val))))0.8218562874251497
0.8295964125560538こうでした、ここの値が近いと精度高い印象です。
そして予測値は、
np.round(pred)array([0., 0., 0., 0., 0., 0., 0., 0., 1., 0., 0., 0., 1., 0., 1., 1., 0.,
0., 0., 1., 0., 0., 1., 1., 1., 0., 1., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 1., 1., 0., 0., 0., 1., 1., 0.,
0., 1., 1., 0., 0., 0., 0., 0., 1., 0., 0., 0., 0., 1., 1., 0., 0.,
1., 1., 0., 0., 0., 0., 1., 0., 0., 1., 0., 0., 1., 0., 0., 0., 0.,
0., 0., 0., 0., 1., 0., 0., 1., 0., 0., 0., 1., 0., 0., 0., 1., 0.,
0., 0., 1., 0., 0., 0., 0., 0., 0., 0., 1., 0., 1., 0., 0., 1., 0.,
1., 1., 0., 1., 0., 0., 0., 0., 0., 0., 0., 0., 1., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 1., 0., 0., 0., 0., 0., 0., 0., 0., 1., 0., 0.,
0., 0., 0., 1., 0., 0., 1., 0., 1., 1., 0., 0., 0., 0., 0., 1., 0.,
0., 0., 0., 0., 0., 1., 1., 1., 1., 1., 0., 0., 1., 0., 1., 0., 1.,
0., 0., 0., 0., 0., 0., 0., 1., 0., 1., 0., 0., 0., 0., 0., 1., 1.,
0., 0., 1., 0., 1., 0., 0., 0., 0., 1., 0., 0., 0., 0., 1., 0., 1.,
0., 1., 0., 1., 1., 0., 0., 0., 0., 0., 1., 0., 0., 0., 0., 0., 0.,
1., 1., 1., 1., 0., 0., 0., 0., 1., 0., 1., 1., 1., 0., 1., 0., 0.,
0., 0., 0., 1., 0., 0., 0., 1., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
1., 0., 0., 1., 0., 0., 0., 0., 0., 0., 0., 1., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 1., 0., 0., 0., 0., 0., 0., 0., 1., 1.,
0., 0., 0., 0., 0., 0., 0., 0., 1., 1., 0., 0., 0., 0., 0., 0., 0.,
0., 1., 0., 1., 0., 0., 0., 1., 0., 0., 1., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 1., 0., 0., 0., 1., 0., 1., 1., 0., 0., 0., 1., 0., 1.,
0., 0., 0., 0., 1., 1., 0., 1., 0., 0., 0., 1., 0., 0., 1., 0., 0.,
1., 1., 0., 0., 0., 0., 0., 0., 0., 0., 0., 1., 0., 0., 0., 0., 0.,
1., 0., 0., 0., 1., 0., 1., 0., 0., 1., 0., 1., 0., 0., 0., 0., 0.,
1., 0., 0., 1., 0., 0., 1., 0., 0., 1.])これを整数にしたり(これやらないと正解率0%なってしまいます!)、乗客IDとくっつけたりして
サブミット!!!


