
カグルにこんなんありました『Spaceship Titanic』。概要には、こんなん書いてあります。
宇宙の謎を解くためにデータサイエンスのスキルが必要な2912年へようこそ。4光年離れた場所から送信を受信しましたが、状況は良くありません。
https://www.kaggle.com/competitions/spaceship-titanic/overview
船は、太陽系から近くの星を周回する3つの新しく居住可能な太陽系外惑星に移民を輸送する処女航海に出発しました。
最初の目的地であるかに座55番星に向かう途中でアルファケンタウリを丸めている間、不注意な宇宙船タイタニックは、塵の雲の中に隠された時空の異常と衝突しました。悲しいことに、それは1000年前の同名の人と同じような運命をたどりました。船は無傷のままでしたが、乗客のほぼ半数が別の次元に輸送されました!
なるほど、そういう設定ですか。船は無傷だけど、何人か別の次元?にいっちゃったと。
テストデータで、別次元にいっちゃった人を予測せよ、ということですね。
前回の
『【kaggle】タイタニックデータで81.100% lightGBM×OPTUNA×交差検証』
こちらと同じ作戦でやっていこうと思います。
データの確認やら欠損値補完やら
!pip install optunaimport numpy as np
import pandas as pd
import matplotlib.pyplot as plt
plt.style.use("ggplot")
import optuna
import seaborn as snsレギュラーメンバーをインポート、
df_train=pd.read_csv("/content/drive/MyDrive/Colab Notebooks/Machine Learning/data/kaggle/spacetitanic/train.csv")
df_test=pd.read_csv("/content/drive/MyDrive/Colab Notebooks/Machine Learning/data/kaggle/spacetitanic/test.csv")データを読み込みます。
df_train.head()| PassengerId | HomePlanet | CryoSleep | Cabin | Destination | Age | VIP | RoomService | FoodCourt | ShoppingMall | Spa | VRDeck | Name | Transported | |
| 0 | 0001_01 | Europa | FALSE | B/0/P | TRAPPIST-1e | 39 | FALSE | 0 | 0 | 0 | 0 | 0 | Maham Ofracculy | FALSE |
| 1 | 0002_01 | Earth | FALSE | F/0/S | TRAPPIST-1e | 24 | FALSE | 109 | 9 | 25 | 549 | 44 | Juanna Vines | TRUE |
| 2 | 0003_01 | Europa | FALSE | A/0/S | TRAPPIST-1e | 58 | TRUE | 43 | 3576 | 0 | 6715 | 49 | Altark Susent | FALSE |
| 3 | 0003_02 | Europa | FALSE | A/0/S | TRAPPIST-1e | 33 | FALSE | 0 | 1283 | 371 | 3329 | 193 | Solam Susent | FALSE |
| 4 | 0004_01 | Earth | FALSE | F/1/S | TRAPPIST-1e | 16 | FALSE | 303 | 70 | 151 | 565 | 2 | Willy Santantines | TRUE |
こういうやつです。
| PassengerId | 乗客ID |
| HomePlanet | 乗客が乗船した惑星 |
| CryoSleep | コールドスリープ状態にあるか |
| Cabin | 乗客が滞在しているキャビン番号 |
| Destination | 目的地 |
| Age | 年齢 |
| VIP | VIP客かどうか |
| RoomService | ルームサービスで支払った金額 |
| FoodCourt | フードコートで支払った金額 |
| ShoppingMall | モールで支払った金額 |
| Spa | スパで支払った金額 |
| VRDeck | VRデッキで支払った金額 |
| Name | 名前 |
| Transported | 別次元に飛ばされたか(目的変数) |
テストの方には、目的変数が入っていません。
df_train.info()<class 'pandas.core.frame.DataFrame'>
RangeIndex: 8693 entries, 0 to 8692
Data columns (total 14 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 PassengerId 8693 non-null object
1 HomePlanet 8492 non-null object
2 CryoSleep 8476 non-null object
3 Cabin 8494 non-null object
4 Destination 8511 non-null object
5 Age 8514 non-null float64
6 VIP 8490 non-null object
7 RoomService 8512 non-null float64
8 FoodCourt 8510 non-null float64
9 ShoppingMall 8485 non-null float64
10 Spa 8510 non-null float64
11 VRDeck 8505 non-null float64
12 Name 8493 non-null object
13 Transported 8693 non-null bool
dtypes: bool(1), float64(6), object(7)
memory usage: 891.5+ KBdf_test["Transported"]=np.nanNANで入れといて、
df_test.info()<class 'pandas.core.frame.DataFrame'>
RangeIndex: 8693 entries, 0 to 8692
Data columns (total 14 columns):
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 4277 entries, 0 to 4276
Data columns (total 14 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 PassengerId 4277 non-null object
1 HomePlanet 4190 non-null object
2 CryoSleep 4184 non-null object
3 Cabin 4177 non-null object
4 Destination 4185 non-null object
5 Age 4186 non-null float64
6 VIP 4184 non-null object
7 RoomService 4195 non-null float64
8 FoodCourt 4171 non-null float64
9 ShoppingMall 4179 non-null float64
10 Spa 4176 non-null float64
11 VRDeck 4197 non-null float64
12 Name 4183 non-null object
13 Transported 0 non-null float64
dtypes: float64(7), object(7)
memory usage: 467.9+ KBカラムがそろったので、目印をつけてがっちゃんこします。
df_train["train/test"]="train"
df_test["train/test"]="test"df_all=pd.concat([df_train,df_test])df_all=df_all.reset_index(drop=True)このデータで各々を見ていきます。
PassengerId
アンダースコアで2つの数字がくっついているので分けます。
df_all["ID01"]=df_all["PassengerId"].str.split("_",expand=True)[0]
df_all["ID02"]=df_all["PassengerId"].str.split("_",expand=True)[1]df_all.info()<class 'pandas.core.frame.DataFrame'>
RangeIndex: 12970 entries, 0 to 12969
Data columns (total 17 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 PassengerId 12970 non-null object
1 HomePlanet 12682 non-null object
2 CryoSleep 12660 non-null object
3 Cabin 12671 non-null object
4 Destination 12696 non-null object
5 Age 12700 non-null float64
6 VIP 12674 non-null object
7 RoomService 12707 non-null float64
8 FoodCourt 12681 non-null float64
9 ShoppingMall 12664 non-null float64
10 Spa 12686 non-null float64
11 VRDeck 12702 non-null float64
12 Name 12676 non-null object
13 Transported 8693 non-null float64
14 train/test 12970 non-null object
15 ID01 12970 non-null object
16 ID02 12970 non-null object
dtypes: float64(7), object(10)
memory usage: 1.7+ MBobjectなので数字にします。
df_all["ID01"]=df_all["ID01"].astype(int)
df_all["ID02"]=df_all["ID02"].astype(int)ひとまずカグルに提出してみたいので、ID02の方だけ使います。
plt.figure(figsize=(16,9))
sns.countplot(df_all["ID02"],hue=df_all["Transported"])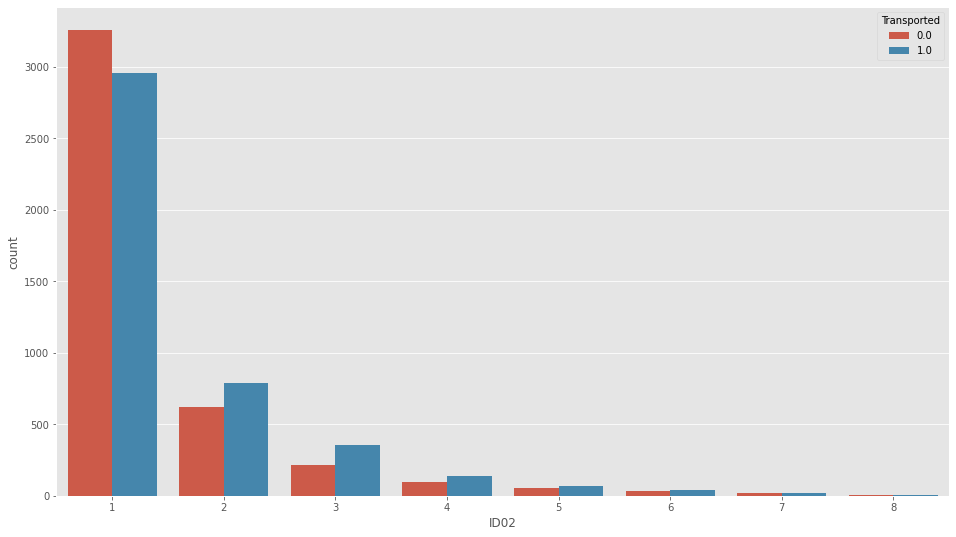
微妙に相関ありそうです。
HomePlanet
欠損数がそこまで多くないので、最頻値で埋めます。
plt.figure(figsize=(16,9))
sns.countplot(df_all["HomePlanet"],hue=df_all["Transported"])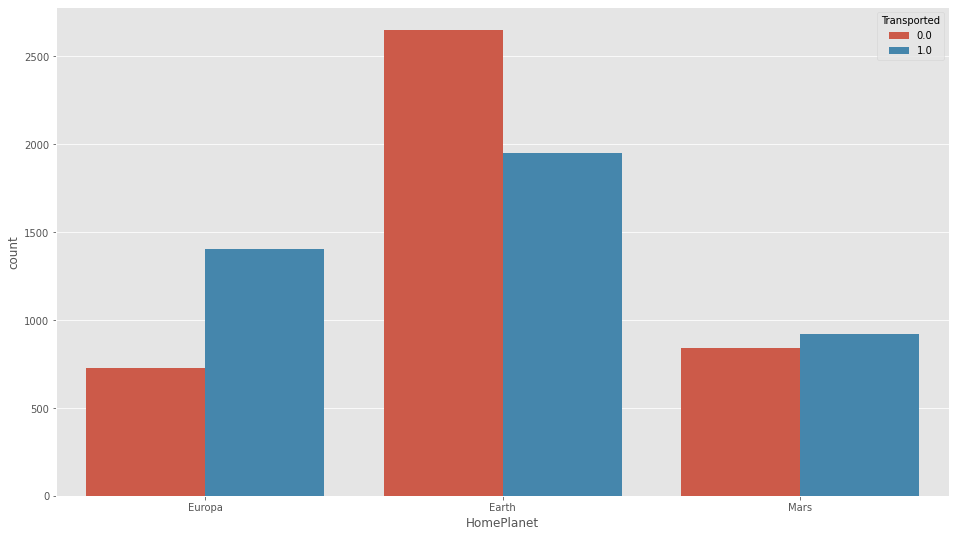
df_all["HomePlanet"].fillna("Earth",inplace=True)CryoSleep
これも最頻値で埋めます。
df_all["Nameini"]=df_all["Name"]plt.figure(figsize=(16,9))
sns.countplot(df_all["CryoSleep"],hue=df_all["Transported"])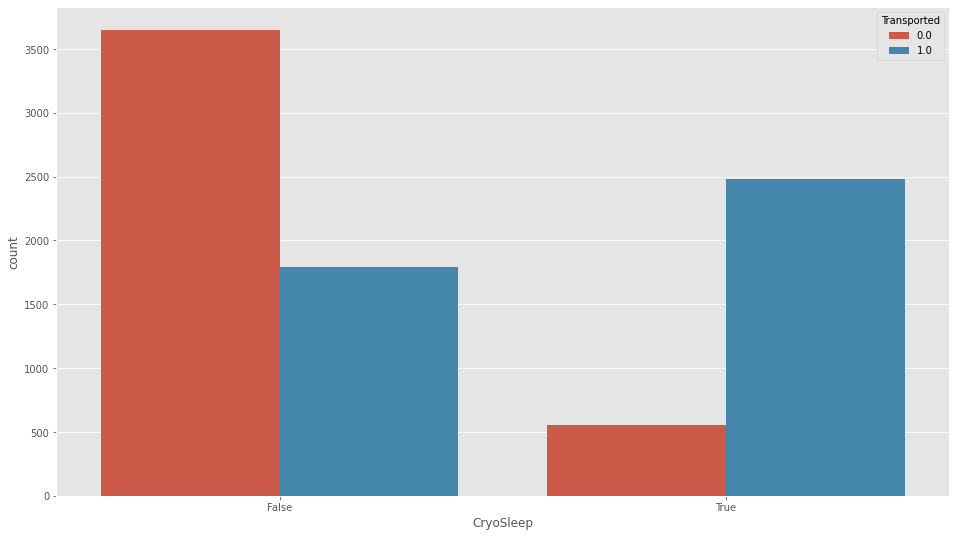
df_all["CryoSleep"].fillna("False",inplace=True)objectなのでboolに変換しておきます。
df_all["CryoSleep"]=df_all["CryoSleep"].astype(bool)コールドスリープ状態の方のほうが、高い割合で別次元にいっているようです。
Cabin
さて、この子です。見るからに情報持ってます、という感じですね。
/で分けます。
df_all["Cabin1"]=df_all["Cabin"].str.split("/",expand=True)[0]
df_all["Cabin2"]=df_all["Cabin"].str.split("/",expand=True)[1]
df_all["Cabin3"]=df_all["Cabin"].str.split("/",expand=True)[2]まずはCabin1から。
plt.figure(figsize=(16,9))
sns.countplot(df_all["Cabin1"],hue=df_all["Transported"])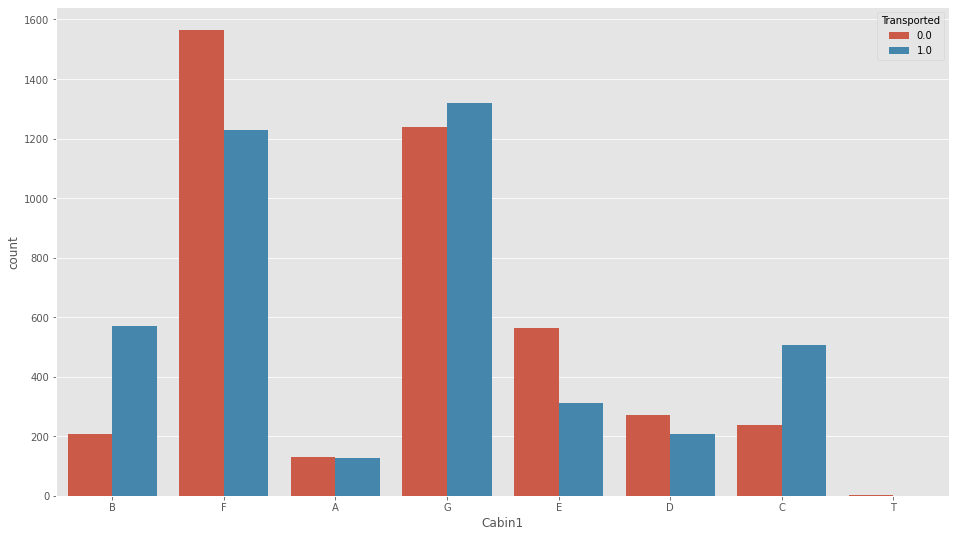
キャビンの区画的なものでしょうか、特徴でてます。
最頻値で埋めます。
df_all["Cabin1"].fillna("F",inplace=True)次に、Cabin3
plt.figure(figsize=(16,9))
sns.countplot(df_all["Cabin3"],hue=df_all["Transported"])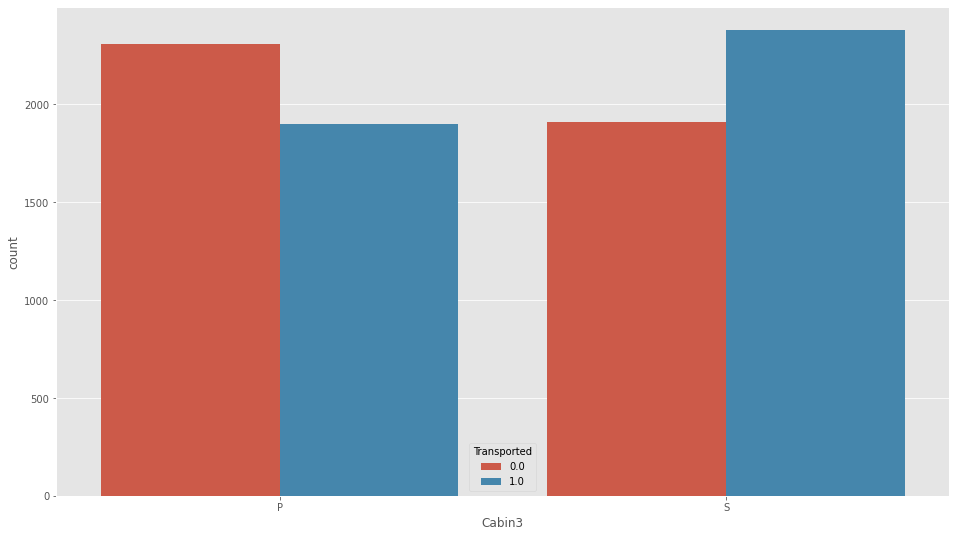
df_all["Cabin3"].value_counts()S 6381
P 6290
Name: Cabin3, dtype: int64これも最頻値で埋めます。
df_all["Cabin3"].fillna("S",inplace=True)最後に、Cabin2
df_all["Cabin2"].value_counts()82 34
4 28
56 28
95 27
31 27
..
1848 1
1847 1
1846 1
1844 1
1890 1
Name: Cabin2, Length: 1894, dtype: int64こんな感じなので、ひとまず欠損してるところをない値で埋めます。
df_all["Cabin2"].fillna(2000,inplace=True)数字にして、
df_all["Cabin2"]=df_all["Cabin2"].astype(int)分布を見ます。
plt.figure(figsize=(16,9))
plt.hist(df_all["Cabin2"],bins=350,color="blue")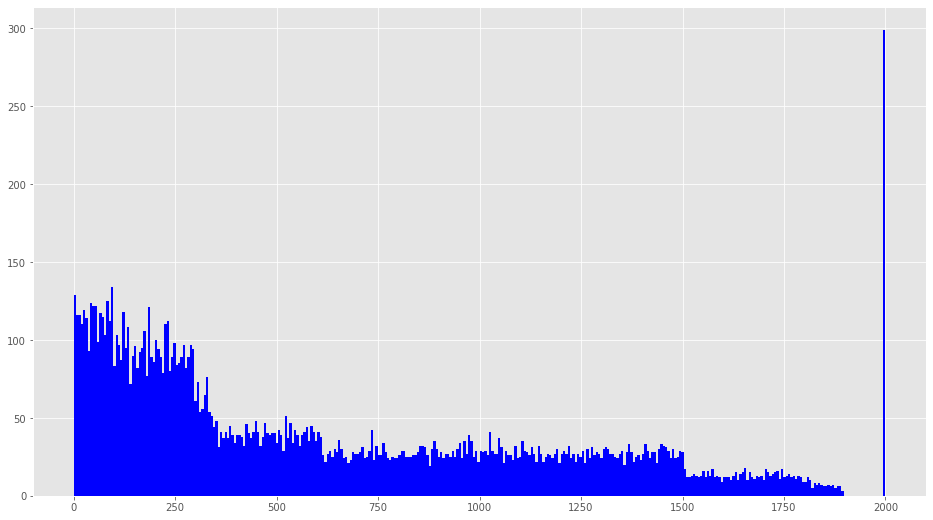
なんとなく、4つのグループに分けれそうです。
df_all.loc[(0<=df_all["Cabin2"])&(df_all["Cabin2"]<350),"Cabin2"]=1
df_all.loc[(350<=df_all["Cabin2"])&(df_all["Cabin2"]<600),"Cabin2"]=2
df_all.loc[(600<=df_all["Cabin2"])&(df_all["Cabin2"]<1500),"Cabin2"]=3
df_all.loc[(1500<=df_all["Cabin2"])&(df_all["Cabin2"]<2000),"Cabin2"]=4目視でこんな感じ分けます。
df_all["Cabin2"].value_counts()1 5776
3 4352
2 1729
4 814
2000 299
Name: Cabin2, dtype: int641グループが一番多いのでこれで埋めることにします。
df_all.loc[df_all["Cabin2"]==2000,"Cabin2"]=1plt.figure(figsize=(23,9))
sns.countplot(df_all["Cabin2"],hue=df_all["Transported"])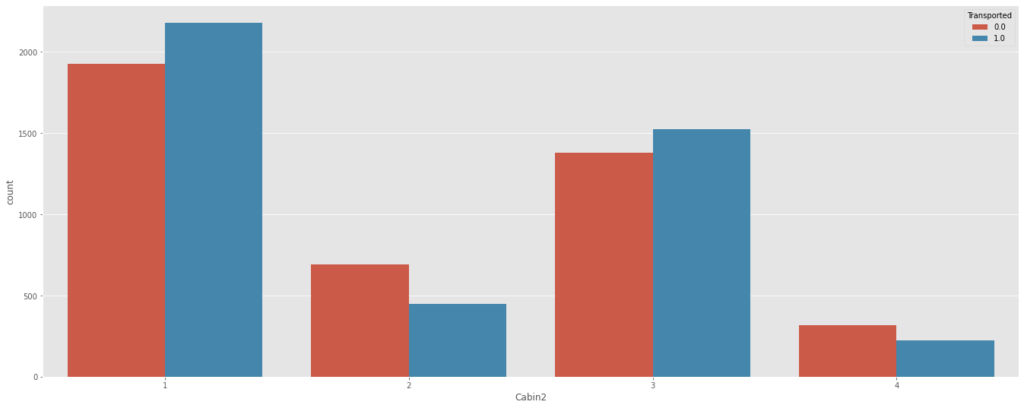
それなりに特徴つかんでいるでしょう。
Destination
これも最頻値で埋めます。
plt.figure(figsize=(16,9))
sns.countplot(df_all["Destination"],hue=df_all["Transported"])
df_all["Destination"].fillna("TRAPPIST-1e",inplace=True)VIP
これも最頻値で埋めます。
df_all["Family"]=dfplt.figure(figsize=(16,9))
sns.countplot(df_all["VIP"],hue=df_all["Transported"])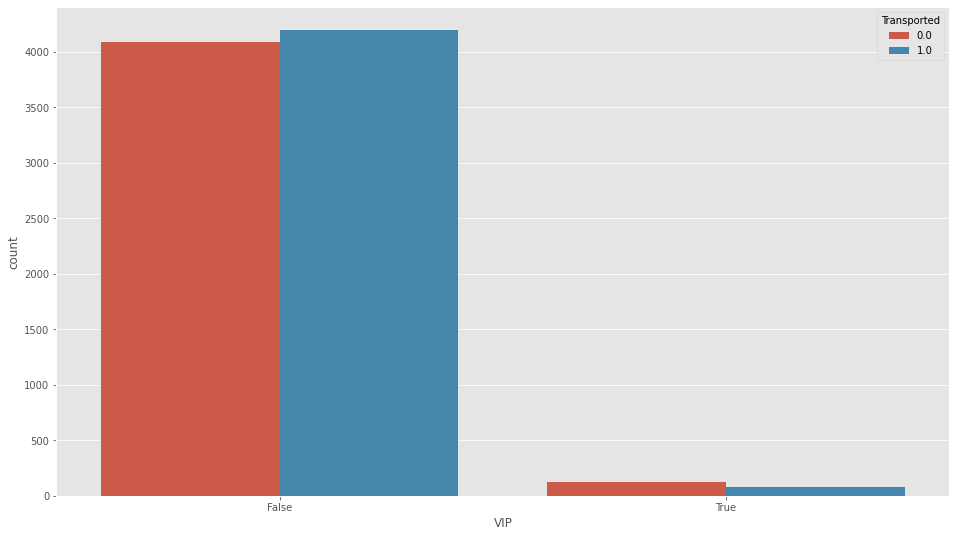
df_all["VIP"].fillna("False",inplace=True)objectなのでboolに変換しておきます。
df_all["VIP"]=df_all["VIP"].astype(bool)RoomServiceからVRDeckまで
これらはすべて中央値で埋めます。
df_all["RoomService"].fillna(df_all["RoomService"].median(),inplace=True)
df_all["FoodCourt"].fillna(df_all["FoodCourt"].median(),inplace=True)
df_all["ShoppingMall"].fillna(df_all["ShoppingMall"].median(),inplace=True)
df_all["Spa"].fillna(df_all["Spa"].median(),inplace=True)
df_all["VRDeck"].fillna(df_all["VRDeck"].median(),inplace=True)合計の特徴量をつくっておきます。
df_all["pay"]=df_all["RoomService"]+df_all["FoodCourt"]+df_all["ShoppingMall"]+df_all["Spa"]+df_all["VRDeck"]ようやくデータの整理ができました。記事がかなり長くなってしまうので
学習やら結果やらは次回に回します。
df_all.info()<class 'pandas.core.frame.DataFrame'>
RangeIndex: 12970 entries, 0 to 12969
Data columns (total 21 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 PassengerId 12970 non-null object
1 HomePlanet 12970 non-null object
2 CryoSleep 12970 non-null bool
3 Cabin 12671 non-null object
4 Destination 12970 non-null object
5 Age 12970 non-null float64
6 VIP 12970 non-null bool
7 RoomService 12970 non-null float64
8 FoodCourt 12970 non-null float64
9 ShoppingMall 12970 non-null float64
10 Spa 12970 non-null float64
11 VRDeck 12970 non-null float64
12 Name 12676 non-null object
13 Transported 8693 non-null float64
14 train/test 12970 non-null object
15 ID01 12970 non-null int64
16 ID02 12970 non-null int64
17 Cabin1 12970 non-null object
18 Cabin2 12970 non-null int64
19 Cabin3 12970 non-null object
20 pay 12970 non-null float64
dtypes: bool(2), float64(8), int64(3), object(8)
memory usage: 1.9+ MB
